
这次分享的知识属于特别基础,但又不是每个人都了解清楚的,而且很少人从这方面来思考爬虫和互联网和外链的关系,所以才有了本文。
如果文中有一些细节错误,请在评论区指出。
HTTP 协议、互联网、爬虫、外链。
看起来几个不相关的东西,其实对我们做网站很重要。
总有朋友问,为什么在 Ahrefs 看到了的外链,在 GSC 上看不到,其实原因就是因为爬虫还没爬到。
要解释为什么还没爬到,就需要解释互联网到底是个啥玩意儿。
所以今天的小课堂,是科普性质的,我尽量用我的语言讲得通俗易懂一点。
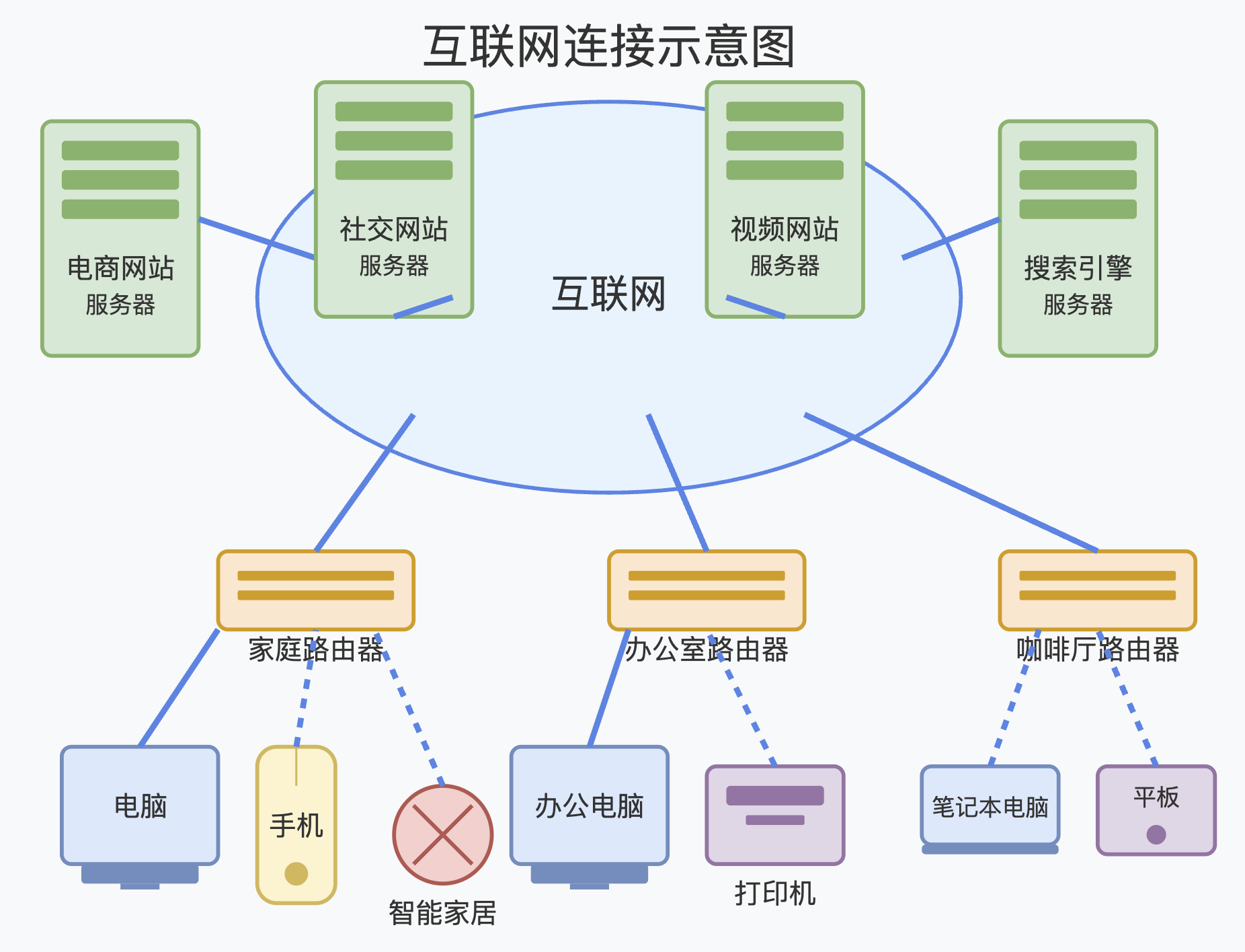
互联网,互联网,顾名思义,就是一张互联连接起来的网。
这里的网,既可以认为是网线,也可以认为是链接。
一个是实体,一个是虚拟。
世界上所有的计算机,通过网线、光纤、光缆链接起来了,这是实体的链接。
备注:图片由 Claude 生成,能够理解意思即可,细节不用深究,下文所有图片同理
而互联网,正是建立在这个实体网络上的。
每一个网站,都部署在某一台或者某几台服务器上,通过网线连入整个互联网。
而一个网站,少则一个网页,多个几十个,几百个,几万个,几千万个网页。
这些网页之间,通过链接来互相连接。
正是因为有了这些链接,整个互联网,才能称之为真正的互通互联。
服务器,其实也是计算机,只不过是一般不关机,持久长期运行的计算机。
专门用于处理网络请求。
你甚至可以把你自己的电脑通过一些工具,连入互联网,让别人能够通过网络来请求你的电脑。
不过这里我们不展开。
什么是网络请求?
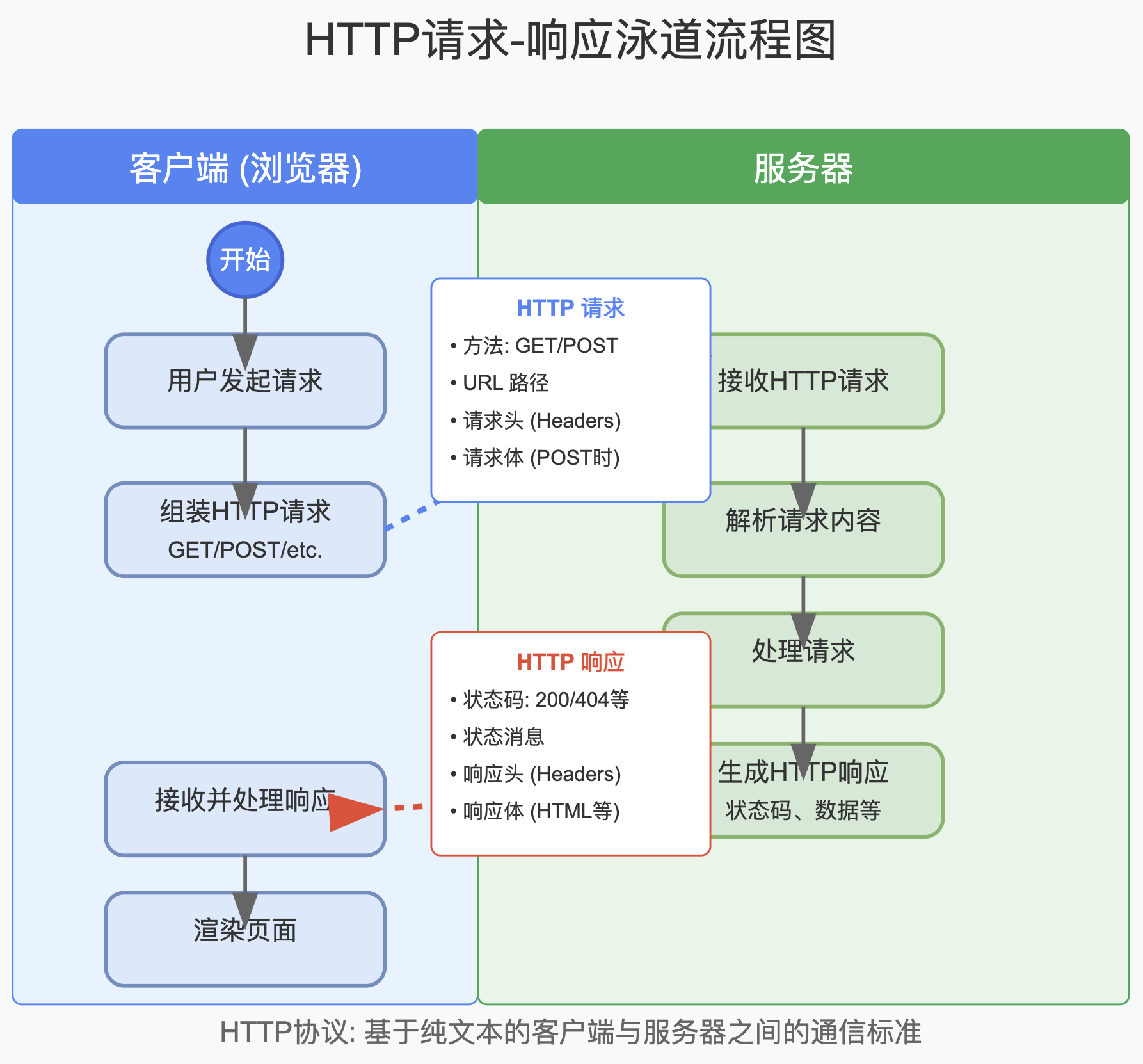
你用浏览器打开一个网页,其实就是由你的浏览器作为客户端,向这个网页所在的服务器,发起一个网络请求,来获取网页 HTML 源码。
这是获取数据,所以是 GET 形式的请求。
你打开推特网页,使用网页里的输入框,发布了一条推文,其实也是一次网络请求。
这是提交数据,所以一般用 POST 形式的请求。
你在你的服务器里调用某个 API ,其实也是发起一个网络请求,这次的请求虽然是服务器到服务器,但其实也分客户端和服务端,你的服务器作为请求的发起方,就是客户端,提供 API 服务的那台服务器,就是服务端。
而请求的具体格式,就是由 HTTP 协议规定的。
所有客户端发出的请求,都遵循 HTTP 协议,所有的服务端响应请求时,也遵循 HTTP 协议。
HTTP 全称 超文本传输协议 ,是明文纯文本协议,也就是发出的数据,返回的数据,其实都是文本格式。
即使我们上传的是图片等二进制数据,有时也会通过 Base64 等编码方式转换为文本格式来传输。
如果是 HTTPS ,则在客户端和服务端进行了加解密,加密后传输的是二进制数据。
HTTP 协议的具体格式,我们今天不展开,感兴趣的朋友可以去自学。
我们只需要知道,网站,其实是由一个一个网页构成的,而每一个网页,返回给客户端的,其实都是 HTML 代码,也是纯文本的,肉眼可以读取和解析的。
浏览器去解析 HTML 文本,之后渲染为丰富多彩的,可以互动操作的网页。
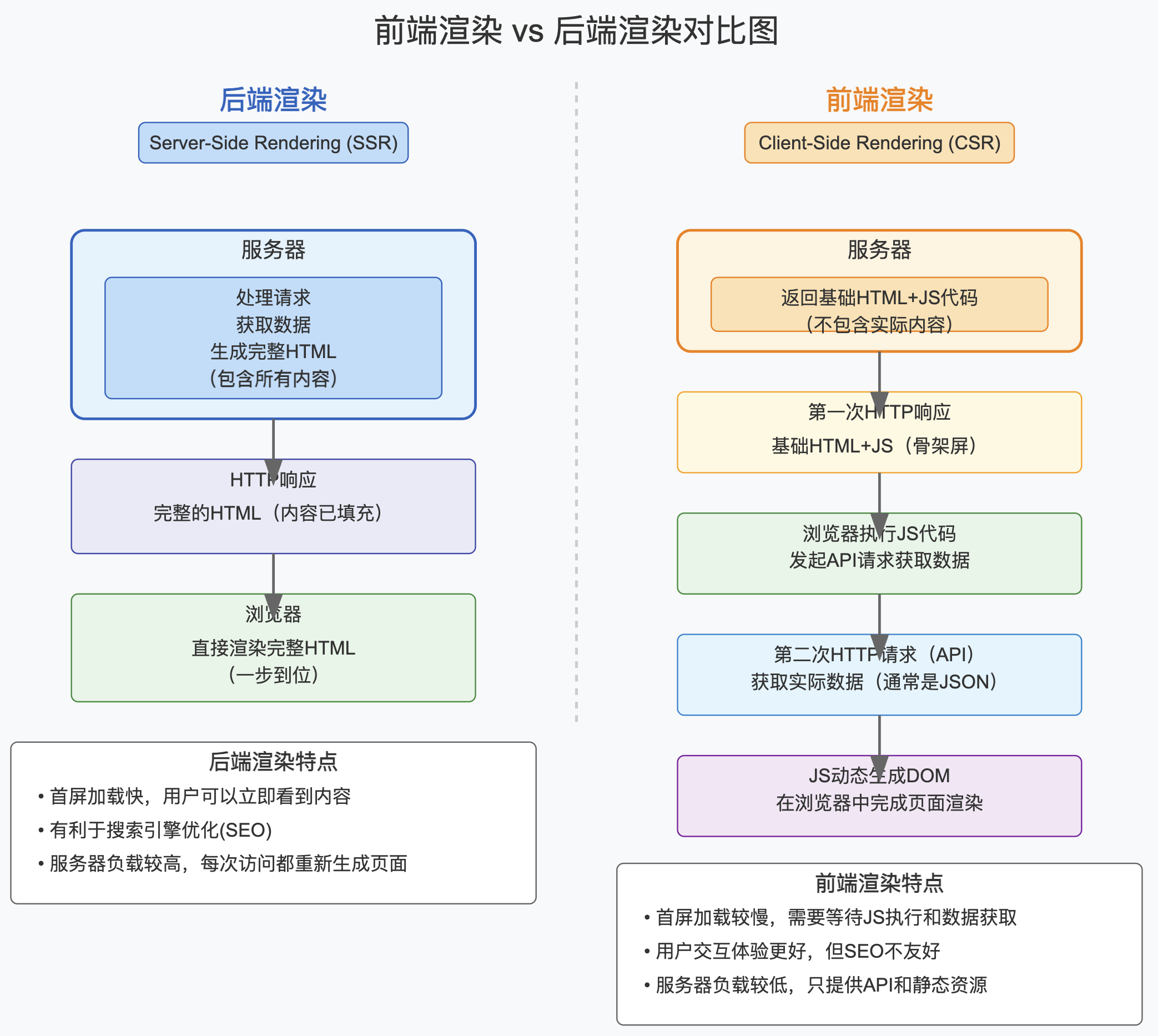
我们常说的后端渲染,就是浏览器发起一个请求后,返回的网页是完整的内容,所有最终渲染出来的,都由后端在 html 里一一返回。
而前端渲染,通常分成两步,第一步浏览器请求时,返回一个 HTML 网页基本内容以及一段 js 代码。
第二步,浏览器解析并且执行 JS 代码,按需再发起新的请求,获取数据之后,在 JS 里组装好 HTML 内容,由浏览器在前端插入到网页的合适位置,最后渲染出来。
互联网,并没有一个统一的数据库。
所有网站和网页都是分散在整个互联网上的各个不同的服务器里的。
没有谁能够清楚的说出全世界总共有多少个网站,有多少网页。
如果有一家公司,想要知道整个互联网上到底有多少网页,就需要派出爬虫,一个一个网页去爬。
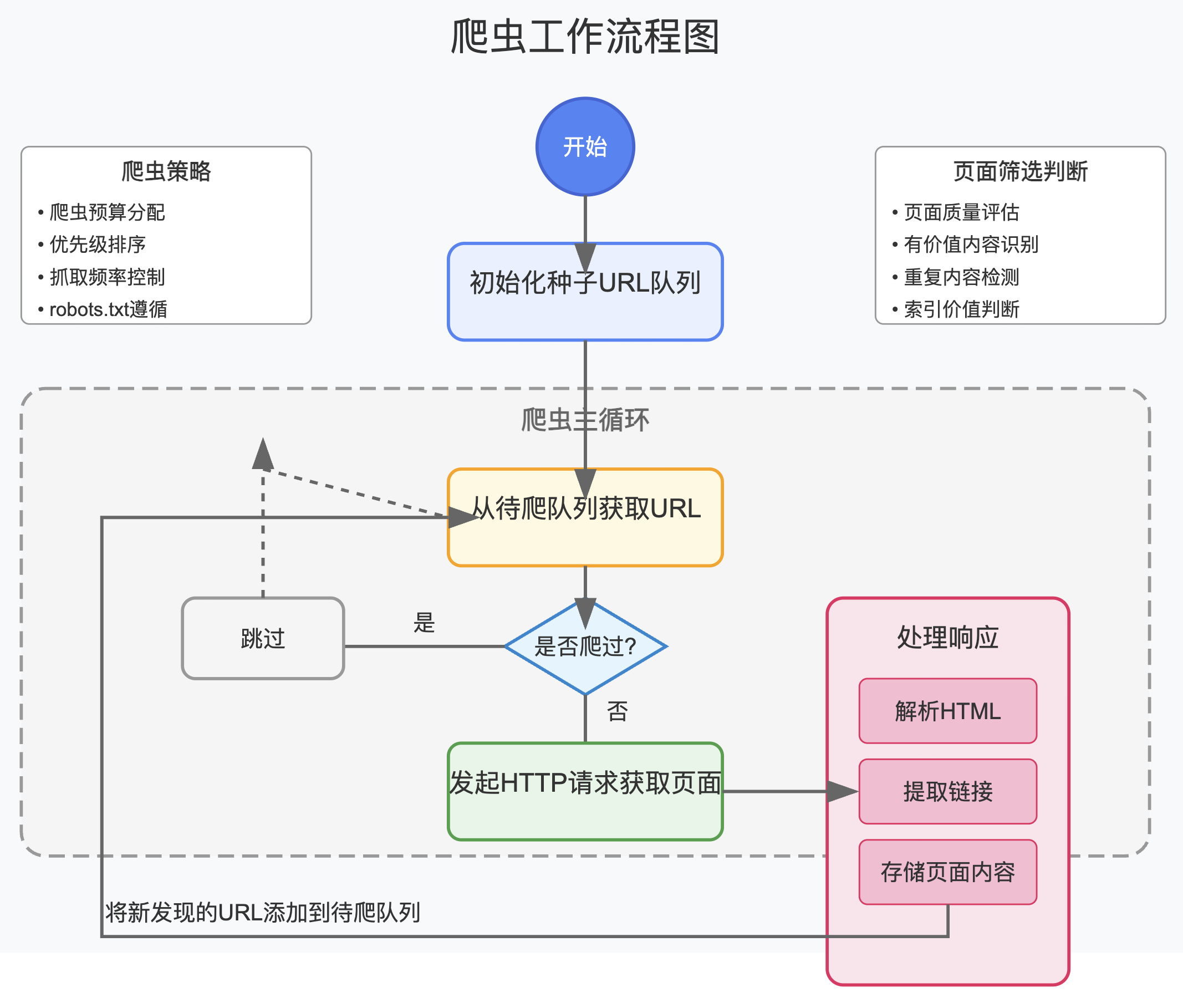
这里的爬,其实就是发起一个网络请求,获取网页 HTML 代码。
之后解析 HTML 代码,提取里边的链接,查看是否已经抓取,如果是已经抓取过的网页,就去看是否需要再次抓取,如果是没抓取过的,就需要判断是否需要去抓取。
对于需要抓取的,就放到待爬列表里去。
之后,不断的从待爬列表,拿任务,不断的爬。
爬网页,刚说了,其实是发出请求,下载 HTML 代码。
这就需要消耗资源,所以如果想要爬完整个互联网,需要花特别多的资源,资源就是钱,也就是说,需要花很多钱。
所以这里会有一些判断规则,各家的策略都不一样,目的都是找出值得去爬的网页,尽可能的减少成本。
对于谷歌的爬虫来说,分配给每一个网站的爬虫预算都是不一样的,有些新网站,爬虫预算少,有些高权重网站,爬虫预算就高。
如果你的网站,在大量生成质量低的页面,谷歌一开始爬了之后,发现你的网页都拿不到排名,之后就会调低你的预算,不再爬新的网页。
对于已经爬了的网页,也可能不索引。
对于已经索引了的网页,也可能删除索引。
这时候,你的 GSC 里的网页索引里,就会看到未索引页面在不断增长。
如果你无视这些信号,还在持续不断的生成同样的低质量页面,谷歌就会对你的网站进行惩罚,不给你曝光了,目的也是提醒你,要有点自觉,别再生成垃圾页面了。
刚才说了,各家的爬虫都是独立运行的。
所以谷歌的爬虫爬到了的网页,Ahrefs 家的爬虫不一定爬到了。
同样的,Ahrefs 家爬虫爬到了的网页,谷歌的爬虫不一定爬到了。
另外,谷歌 GSC 里显示的外链(反向链接),是有延迟的,并不是爬虫抓取到了,就立马显示出来了。
而 Ahrefs 等 SEO 数据平台的反链,会更实时的放出来。
基于以上两个原因,一、爬虫独立运行; 2 、数据显示时间不一致,就会导致大家在各个平台看到的数据不一致。
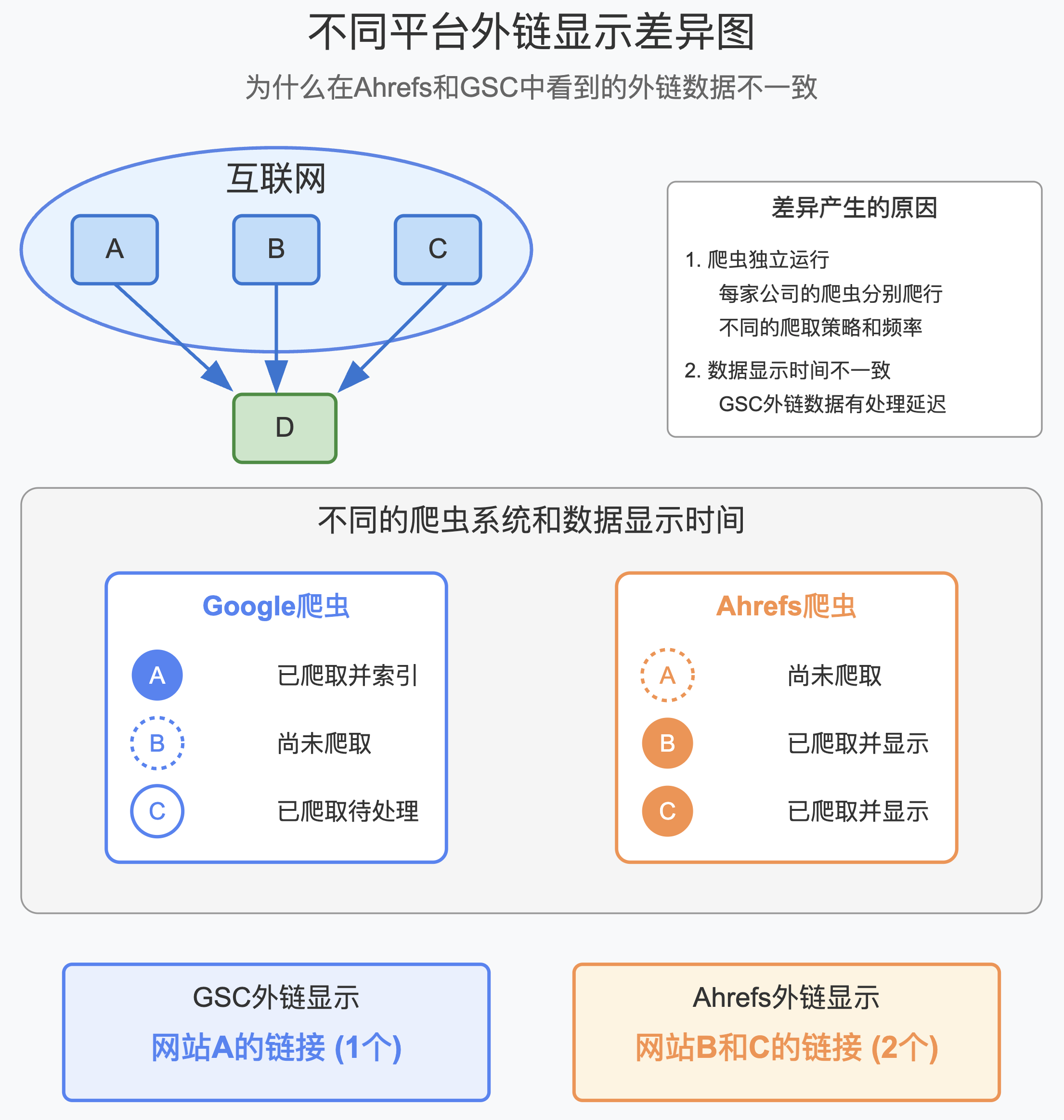
举例,你在 ABC 三个网站给你的 D 网站加了外链,过两天,你去 Ahrefs 查,可能看到了 BC 出来了,A 还没出来,而去 GSC 查,可能一个都看到,或者只看到了 A ,或者只看到了 B ,都是有可能的。
为什么现在大家做 AI 搜索,不会想着去自建一个爬虫?
原因就是上面说的,如果想要建一个把全网所有网页都爬完的爬虫系统,需要的费用会是天价的。
所以 ChatGPT 会选择用 Bing 的搜索接口,有些别的 AI 搜索可能会选择 Google 的接口,或者别的搜索引擎的接口。
但是 OpenAI 是有爬虫的,他的目的不是爬完全网的所有网页,而是去爬一些指定的,有着高质量内容的网页,用于构建训练模型所需要的数据集。
以及,当我们提出让 GPT 去搜索总结一些网页时,实时的去抓取网页内容。
以上就是今天的哥飞小课堂内容,主要是给大家科普一下,网站到底是个什么东西,互联网到底是怎么互联的。
理解了这些基础概念,对于大家做好 SEO ,是有帮助的。
而且程序员学好了 SEO ,就有了不依赖平台而独自生存的能力。
哥飞祝愿每一位程序员,都能得偿所愿。
如果文中有一些细节错误,请在评论区指出。
HTTP 协议、互联网、爬虫、外链。
看起来几个不相关的东西,其实对我们做网站很重要。
总有朋友问,为什么在 Ahrefs 看到了的外链,在 GSC 上看不到,其实原因就是因为爬虫还没爬到。
要解释为什么还没爬到,就需要解释互联网到底是个啥玩意儿。
所以今天的小课堂,是科普性质的,我尽量用我的语言讲得通俗易懂一点。
互联网,互联网,顾名思义,就是一张互联连接起来的网。
这里的网,既可以认为是网线,也可以认为是链接。
一个是实体,一个是虚拟。
世界上所有的计算机,通过网线、光纤、光缆链接起来了,这是实体的链接。

备注:图片由 Claude 生成,能够理解意思即可,细节不用深究,下文所有图片同理
而互联网,正是建立在这个实体网络上的。
每一个网站,都部署在某一台或者某几台服务器上,通过网线连入整个互联网。
而一个网站,少则一个网页,多个几十个,几百个,几万个,几千万个网页。
这些网页之间,通过链接来互相连接。
正是因为有了这些链接,整个互联网,才能称之为真正的互通互联。
服务器,其实也是计算机,只不过是一般不关机,持久长期运行的计算机。
专门用于处理网络请求。
你甚至可以把你自己的电脑通过一些工具,连入互联网,让别人能够通过网络来请求你的电脑。
不过这里我们不展开。
什么是网络请求?

你用浏览器打开一个网页,其实就是由你的浏览器作为客户端,向这个网页所在的服务器,发起一个网络请求,来获取网页 HTML 源码。
这是获取数据,所以是 GET 形式的请求。
你打开推特网页,使用网页里的输入框,发布了一条推文,其实也是一次网络请求。
这是提交数据,所以一般用 POST 形式的请求。
你在你的服务器里调用某个 API ,其实也是发起一个网络请求,这次的请求虽然是服务器到服务器,但其实也分客户端和服务端,你的服务器作为请求的发起方,就是客户端,提供 API 服务的那台服务器,就是服务端。
而请求的具体格式,就是由 HTTP 协议规定的。
所有客户端发出的请求,都遵循 HTTP 协议,所有的服务端响应请求时,也遵循 HTTP 协议。
HTTP 全称 超文本传输协议 ,是明文纯文本协议,也就是发出的数据,返回的数据,其实都是文本格式。
即使我们上传的是图片等二进制数据,有时也会通过 Base64 等编码方式转换为文本格式来传输。
如果是 HTTPS ,则在客户端和服务端进行了加解密,加密后传输的是二进制数据。
HTTP 协议的具体格式,我们今天不展开,感兴趣的朋友可以去自学。
我们只需要知道,网站,其实是由一个一个网页构成的,而每一个网页,返回给客户端的,其实都是 HTML 代码,也是纯文本的,肉眼可以读取和解析的。

浏览器去解析 HTML 文本,之后渲染为丰富多彩的,可以互动操作的网页。

我们常说的后端渲染,就是浏览器发起一个请求后,返回的网页是完整的内容,所有最终渲染出来的,都由后端在 html 里一一返回。
而前端渲染,通常分成两步,第一步浏览器请求时,返回一个 HTML 网页基本内容以及一段 js 代码。
第二步,浏览器解析并且执行 JS 代码,按需再发起新的请求,获取数据之后,在 JS 里组装好 HTML 内容,由浏览器在前端插入到网页的合适位置,最后渲染出来。
互联网,并没有一个统一的数据库。
所有网站和网页都是分散在整个互联网上的各个不同的服务器里的。
没有谁能够清楚的说出全世界总共有多少个网站,有多少网页。
如果有一家公司,想要知道整个互联网上到底有多少网页,就需要派出爬虫,一个一个网页去爬。

这里的爬,其实就是发起一个网络请求,获取网页 HTML 代码。
之后解析 HTML 代码,提取里边的链接,查看是否已经抓取,如果是已经抓取过的网页,就去看是否需要再次抓取,如果是没抓取过的,就需要判断是否需要去抓取。
对于需要抓取的,就放到待爬列表里去。
之后,不断的从待爬列表,拿任务,不断的爬。
爬网页,刚说了,其实是发出请求,下载 HTML 代码。
这就需要消耗资源,所以如果想要爬完整个互联网,需要花特别多的资源,资源就是钱,也就是说,需要花很多钱。
所以这里会有一些判断规则,各家的策略都不一样,目的都是找出值得去爬的网页,尽可能的减少成本。
对于谷歌的爬虫来说,分配给每一个网站的爬虫预算都是不一样的,有些新网站,爬虫预算少,有些高权重网站,爬虫预算就高。
如果你的网站,在大量生成质量低的页面,谷歌一开始爬了之后,发现你的网页都拿不到排名,之后就会调低你的预算,不再爬新的网页。
对于已经爬了的网页,也可能不索引。
对于已经索引了的网页,也可能删除索引。
这时候,你的 GSC 里的网页索引里,就会看到未索引页面在不断增长。
如果你无视这些信号,还在持续不断的生成同样的低质量页面,谷歌就会对你的网站进行惩罚,不给你曝光了,目的也是提醒你,要有点自觉,别再生成垃圾页面了。
刚才说了,各家的爬虫都是独立运行的。
所以谷歌的爬虫爬到了的网页,Ahrefs 家的爬虫不一定爬到了。
同样的,Ahrefs 家爬虫爬到了的网页,谷歌的爬虫不一定爬到了。
另外,谷歌 GSC 里显示的外链(反向链接),是有延迟的,并不是爬虫抓取到了,就立马显示出来了。
而 Ahrefs 等 SEO 数据平台的反链,会更实时的放出来。
基于以上两个原因,一、爬虫独立运行; 2 、数据显示时间不一致,就会导致大家在各个平台看到的数据不一致。

举例,你在 ABC 三个网站给你的 D 网站加了外链,过两天,你去 Ahrefs 查,可能看到了 BC 出来了,A 还没出来,而去 GSC 查,可能一个都看到,或者只看到了 A ,或者只看到了 B ,都是有可能的。
为什么现在大家做 AI 搜索,不会想着去自建一个爬虫?
原因就是上面说的,如果想要建一个把全网所有网页都爬完的爬虫系统,需要的费用会是天价的。
所以 ChatGPT 会选择用 Bing 的搜索接口,有些别的 AI 搜索可能会选择 Google 的接口,或者别的搜索引擎的接口。
但是 OpenAI 是有爬虫的,他的目的不是爬完全网的所有网页,而是去爬一些指定的,有着高质量内容的网页,用于构建训练模型所需要的数据集。
以及,当我们提出让 GPT 去搜索总结一些网页时,实时的去抓取网页内容。
以上就是今天的哥飞小课堂内容,主要是给大家科普一下,网站到底是个什么东西,互联网到底是怎么互联的。
理解了这些基础概念,对于大家做好 SEO ,是有帮助的。
而且程序员学好了 SEO ,就有了不依赖平台而独自生存的能力。
哥飞祝愿每一位程序员,都能得偿所愿。
 |
1
potatowish 22 天前 via iPhone
我在群里,估计快到期了。待了一年。
我没赚到钱,主要主业今年太忙了,没时间搞。 但群里信息我基本都看,对我比较大的帮助是,群里分享的一些 AI 相关的工具和方法,对我实际工作有帮助,也拓展了知识面。 |
 |
2
Need4more 22 天前
google 现在直接给出总结了,传统的 seo 价值还有多少呢?
|
 |
3
sentinelK 22 天前
楼主写的不错。很多文章都会轻易陷入到“知识诅咒”中,导致很难树立合理的核心论点。
但就像楼上说的,目前做 seo 的价值已经下降很多了。 据统计,因为谷歌自带 AI 概览,导致 google 的网站点击率降低 30%。 所以我预计,未来的互联网的信息并不是更加拥抱 seo ,而是更加封闭、垂直。 或许“搜索引擎”,乃至信息检索这个领域在几年之内就会名存实亡。 |
 |
4
qiayue OP PRO @potatowish 这条是别人的回复,你复制过来,丝毫不提是复制的,这一点都不 V2EX
你以为这是一条负面评价,其实在我看来,是一条不偏不倚的评价。 他说了忙,没参与,所以没有赚到钱。 赚钱这事,如果自己都不主动,难道还想靠别人给你塞钱吗? |
|
5
qiayue OP PRO @Need4more 其实这个问题,我在多个地方都回答过了。
AI 总结能够解决的一般是咨询信息检索类需求。 而还有很多需求是工具、服务、购物、游戏、下载等等需要网站提供更多交付。 这类需求,AI 可以总结说某某站提供了这个服务,但没办法直接满足用户需求。 用户还是需要点击 AI 推荐的链接,打开网页来满足需求。 我们目前,其实是可以从 AI 推荐得到流量的,随便放张图吧,这是我某个网站各个流量来源渠道情况。 我们有从 ChatGPT 、微软 Copilot 、Perplexity 等渠道获取到流量,虽然暂时还比较少。 更多的还是从谷歌等搜索一群过来的。  |
 |
6
vcbal 22 天前
哥飞 和 飞哥有什么区别,如果是一样的话 我就直接 block 了
|
