
阿里巴巴 CosyVoice3-0.5b 开源了! 现邀请你来体验我做的 Windows 端本地 TTS 工具 3s 音频即可复刻音色 4gb 低显存占用!
Moear · 3 天前 · 1362 次点击阿里巴巴昨天刚开源了 CosyVoice3 ,属实是等了好久了 模型文件可以在huggingface或者modelscope上面下到
来自官方的宣传以及性能对比表格:
Fun-CosyVoice 3.0 是一个基于大型语言模型 (LLM) 的先进文本到语音 (TTS) 系统,在内容一致性、说话人相似度和韵律自然度方面超越了其前身 (CosyVoice 2.0)。它旨在实现零样本多语种野外语音合成。
主要特点
- 语言覆盖范围: 覆盖 9 种常用语言(中文、英语、日语、韩语、德语、西班牙语、法语、意大利语、俄语),18+ 种中国方言/口音(广东、闽南、四川、东北、陕西、山西、上海、天津、山东、宁夏、甘肃等),同时支持多语种/跨语种零样本声音克隆。
- 内容一致性和自然度: 在内容一致性、说话人相似度和韵律自然度方面达到最先进的性能。
- 发音补全: 支持中文拼音和英文 CMU 音素的发音补全,提供更多的可控性,因此适用于生产使用。
- 文本规范化: 支持读取数字、特殊符号和各种文本格式,无需传统的前端模块。
- 双流式处理: 支持文本输入流和音频输出流,并在保持高质量音频输出的同时实现低至 150 毫秒的延迟。
- 指令支持: 支持多种指令,如语言、方言、情感、速度、音量等。
性能表格
| Model | Open-Source | Model Size | test-zh CER (%) ↓ |
test-zh Speaker Similarity (%) ↑ |
test-en WER (%) ↓ |
test-en Speaker Similarity (%) ↑ |
test-hard CER (%) ↓ |
test-hard Speaker Similarity (%) ↑ |
|---|---|---|---|---|---|---|---|---|
| Human | - | - | 1.26 | 75.5 | 2.14 | 73.4 | - | - |
| Seed-TTS | ❌ | - | 1.12 | 79.6 | 2.25 | 76.2 | 7.59 | 77.6 |
| MiniMax-Speech | ❌ | - | 0.83 | 78.3 | 1.65 | 69.2 | - | - |
| F5-TTS | ✅ | 0.3B | 1.52 | 74.1 | 2.00 | 64.7 | 8.67 | 71.3 |
| Spark TTS | ✅ | 0.5B | 1.2 | 66.0 | 1.98 | 57.3 | - | - |
| CosyVoice2 | ✅ | 0.5B | 1.45 | 75.7 | 2.57 | 65.9 | 6.83 | 72.4 |
| FireRedTTS2 | ✅ | 1.5B | 1.14 | 73.2 | 1.95 | 66.5 | - | - |
| Index-TTS2 | ✅ | 1.5B | 1.03 | 76.5 | 2.23 | 70.6 | 7.12 | 75.5 |
| VibeVoice-1.5B | ✅ | 1.5B | 1.16 | 74.4 | 3.04 | 68.9 | - | - |
| VibeVoice-Realtime | ✅ | 0.5B | - | - | 2.05 | 63.3 | - | - |
| HiggsAudio-v2 | ✅ | 3B | 1.50 | 74.0 | 2.44 | 67.7 | - | - |
| VoxCPM | ✅ | 0.5B | 0.93 | 77.2 | 1.85 | 72.9 | 8.87 | 73.0 |
| GLM-TTS | ✅ | 1.5B | 1.03 | 76.1 | - | - | - | - |
| GLM-TTS RL | ✅ | 1.5B | 0.89 | 76.4 | - | - | - | - |
| Fun-CosyVoice3-0.5B-2512 | ✅ | 0.5B | 1.21 | 78.0 | 2.24 | 71.8 | 6.71 | 75.8 |
| Fun-CosyVoice3-0.5B-2512_RL | ✅ | 0.5B | 0.81 | 77.4 | 1.68 | 69.5 | 5.44 | 75.0 |
看到性能表现这么好,今天就有点坐不住,在我之前原有的项目基础上升级了一波(把cosyvoice2模型升级到cosyvoice3 改了几个关键的推理用的代码),现在已经开源放出来了。项目地址在:https://github.com/Moeary/CosyVoiceDesktop
本项目的主要特性
✓ 完全本地部署,无需调用 API
✓ 支持 4 种推理模式:零样本复刻、精细控制、指令控制、语音修补(hotfix,cosyvoice3 新增)
✓ 界面简洁易用,零代码基础即可使用
✓ 支持计划任务批量生成,效果不好可以重 roll ,支持多语言文混合
✓ 国内用户可通过 ModelScope 直接下载模型
✓ 支持 CPU 运行,但有 NVIDIA 的 GPU 会更快(release 包已经内置带 pytorch+cuda 的环境了 理论来说从 20 系到 50 系的支持 cuda12.8 的显卡都能跑,至于为什么选这个是因为 50 系最低的 cuda 限制是 12.8😭)
本项目快速开始
- 下载 Release 包
- 双击 download_all_models.bat 自动下载模型(国内推荐 ModelScope 源)
- 运行 main.py 或双击 StartCosyVoice.bat
- 选择参考音频界面配置一下保存音频设置 → 输入文本 → 点击生成
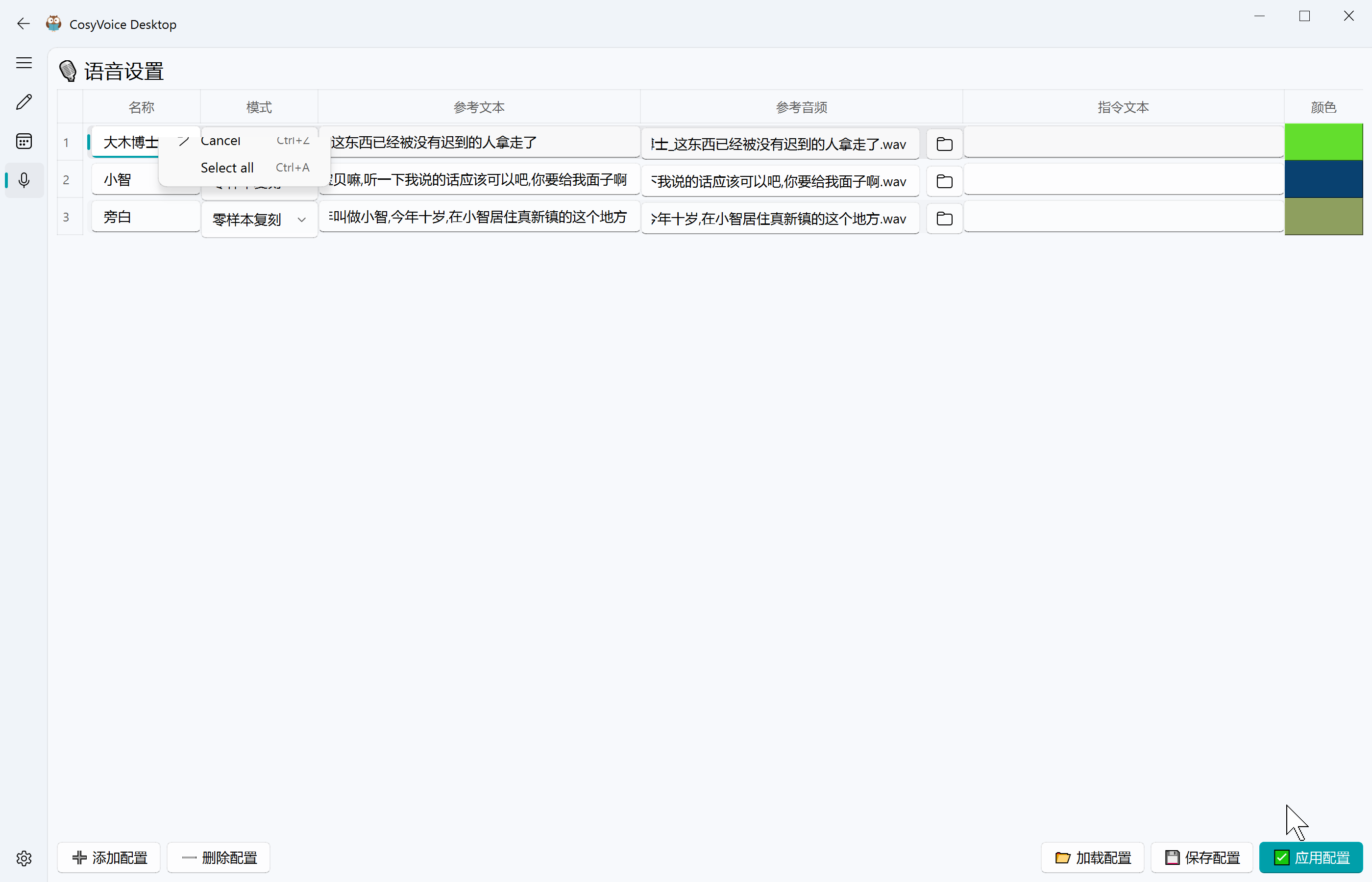
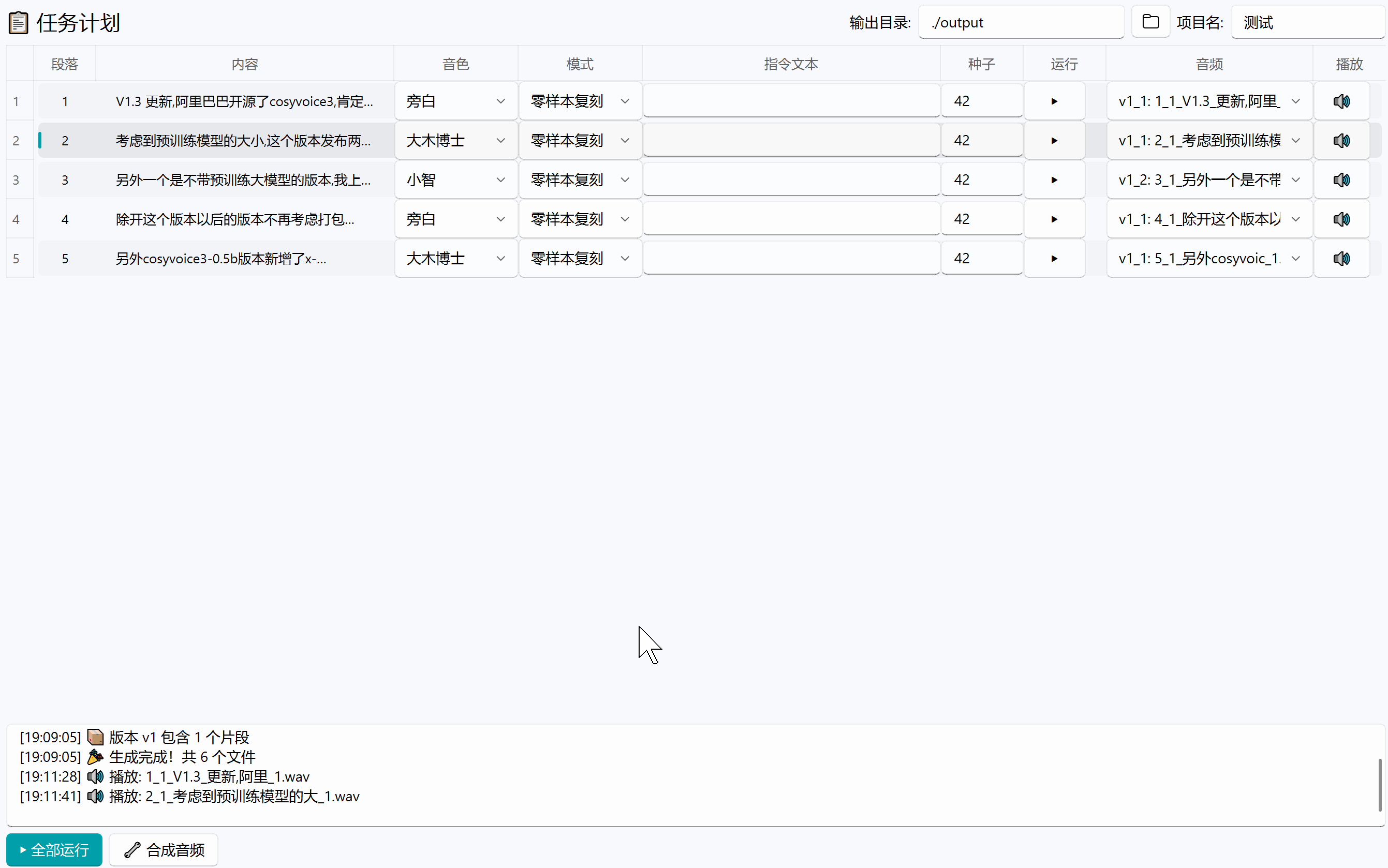
本项目应用场景
可以用于视频配音、游戏 NPC 对白、有声书制作、教程旁白等。
 项目还在不断完善中,欢迎各位提 Issue 和 PR !
项目还在不断完善中,欢迎各位提 Issue 和 PR !
对了,如果觉得有用的话可以给个 Star 支持一下~
28 条回复 • 2025-12-18 16:06:54 +08:00
 |
1
01802 3 天前 via Android
晚上回去试试看
|
 |
2
root71370 3 天前 via Android
有没有好用的语音提取字幕的好用仓库呀
|
 |
3
Moear OP @root71370 可以考虑一下[FunASR]( https://github.com/modelscope/FunASR) 里面带了很多 asr 模型可以直接导入使用,正好昨天新出了一个 FunASR nano 模型来着 做中文识别很不错,可惜暂时还不支持时间戳功能
|
 |
4
noming 3 天前
怎么使用方言?是要自己找方言的示例文件然后放到 asset 文件夹后使用吗?
|
 |
6
Bantes 3 天前
没使用场景,只能自娱自乐了
|
 |
7
Frankcox 3 天前
请问有比较简单的微调处理界面工具吗?我一直用 GPT-Sovits 就是因为他的微调比较简单,Zero-Shot 效果一般,我手头有几个小时的音源,想要微调下。
|
|
8
noming 3 天前
参考文本和参考音频必须要填吗?
|
|
12
noming 3 天前
谢谢!
|
 |
14
avrillavigne 2 天前
不错
|
 |
16
Xhack 2 天前
有没有 生成 Moss 的声音
|
 |
17
MindMindMax 2 天前
求教 op ,本地部署的显卡是啥?速度怎样?
|
 |
18
linstrong 2 天前
喜欢这种一键使用的,回去试试
|
|
19
Moear OP @Xhack 可以自行找一段 Moss 的 3s 到 10s 的无底噪的音频截取下来,来源可以是在 b 站搜一下[ [流浪地球①] MOSS/550W 语录/语音集 (自存)] 作为参考音频推理使用 现在的 tts 模型基本都支持了这种无训练方式复刻音色的功能了
|
|
20
Moear OP @MindMindMax 我自己的显卡是 4070m(笔记本 当做 4060ti 8gb 版本就行了) rtf(Real-Time Factor ,实时因子)大致在 0.8~1.6(越低越好 说明推理数值越快 rtf 是 1 的话就说明显卡花 1s 的算力可以推理出 1s 的音频来) 纯靠 cpu 的话我用 q1hy(13900hk es)的 rtf 大概是 10,30s 时间能推理出 3s 的音频来
|
 |
21
shuxge1223 2 天前
有个问题阿 OP ,我对于配音比较细致,这个能不能自定义多音字的标注,数字和英文发音标注,停顿什么的,更细致一些类似于魔音
|
|
22
MindMindMax 2 天前
@Moear 那和我部署在 Apple m4 机器上的 推理的速度差不多啊。
|
|
23
Moear OP @shuxge1223 理论来说用精细控制模式可以做到 但我没咋用过这个精细控制模式
需要额外打标的,标签可以在 https://github.com/FunAudioLLM/CosyVoice/blob/a7d6e2251adb64f7cef595c5c71c5763cb1d162b/cosyvoice/tokenizer/tokenizer.py 里面找到,不过我目前就做了几个简单的打标快捷键,其他的 cosyvoice3 新增的暂时还没拉上来😂 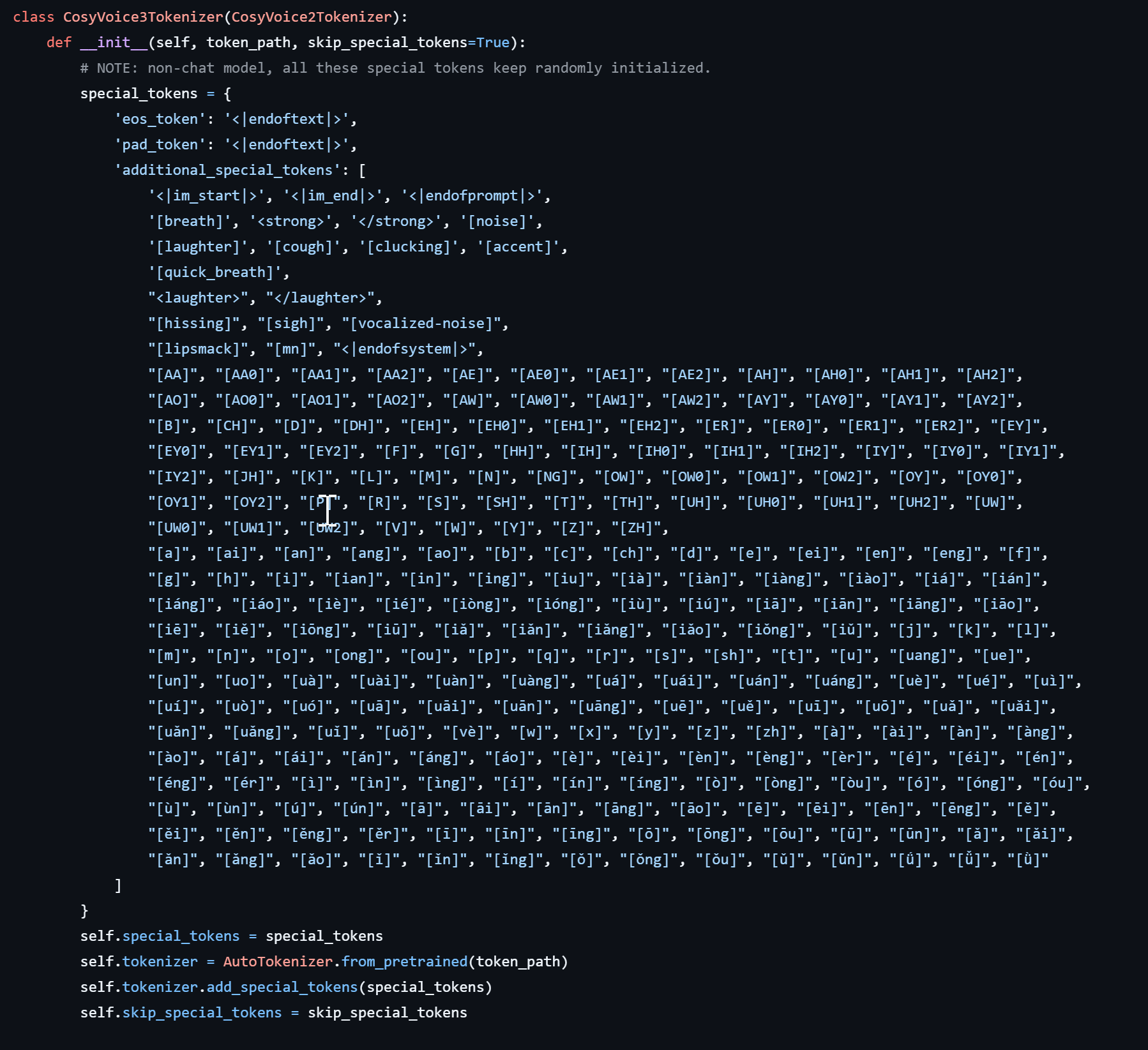    |
|
24
Moear OP @MindMindMax 苹果大带宽的内存跑 ai 啥的还是挺香的😂
|
 |
25
Hansah 1 天前
我看 readme 里面还有个 CosyVoice 3.0-1.5B ?
|
|
27
Hansah 1 天前
这个单条语音最长能生成多久的?试了下,跑的时候大概显存 5-6G ,效果非常好,感觉比 2 好,控制符还有更多的嘛?
|